이 글은 CPU를 보다 심도있게 이해하기 위해서 꼭 알아야하는 Instruction set Architecture와 관련 컴퓨터 구조에 대해서 누구나 이해하기 쉽게 정리하는 글입니다. 글을 쓰는 목적은 전공 공부를 하며 이해하기 힘들었던 부분, 혹은 설명이 어려웠던 부분들을 내가 이해하기 쉽게 정리하기 위함입니다. 이 글의 내용은 고려대학교 정성우 교수님의 "컴퓨터구조" 수업 내용을 들으면서 제가 이해한 것을 바탕으로 정리하였습니다. 교수님의 "명강의"가 저라는 "statement"에 의해 side-effect가 생길수도 있으니 오류가 보이시면 언제든지 지적해주시면 감사하겠습니다. 그러면 시작해보겠습니다.
ISA(Instruction set architecture) 왜 배워야 하는가?
간단하게 생각하면 ISA는 프로세서가 기계어를 이해하는 방식입니다.
음.. 벌써부터 어렵네요. 자, 예시를 들어보겠습니다. 우리가 "프로그램을 실행한다"라고 하는 것은 다음과 같은 다양한 의미를 갖습니다.
고급 언어로 작성된 프로그램이 기계어로 컴파일되어 0과 1로 이루어진 실행가능한 파일이 되었을 때, 이를 CPU의 ALU를 통해 add, sub와 같은 사칙연산을 연산하고, 원하는 메모리 주소로 분기(branch)도 하고 메모리와 레지스터간에 데이터를 Load/Store하는 이러한 모든 일련의 과정들을 보고 프로그램을 실행한다고 말합니다.
여기서 우리가 하드웨어적으로 생각해보면 CPU가 메모리에 적재되어있는 기계어들을 이해하는 방식에 따라 같은 프로그램이라도 다른 output을 내보낸다는 것을 알 수 있습니다. 실제로 같은 기계어라도 ISA가 RISC냐 CISC에 따라 CPU가 다르게 해석합니다. 이렇게 우리가 CPU가 명령어를 해석하는 방식을 배우기 위하여 명령어 집합 아키텍처를 공부하는 것입니다.
제가 사실 앞에서 생략한 부분이 있는데 그것은 바로 고급언어가 컴파일될 때 바로 기계어로 되는 것이 아니라, 어셈블러에 의해서 어셈블리어가 된 후 기계어로 바뀝니다. 그럼 이제 드디어 ISA를 정의할 수 있는데 명령어 집합은 마이크로프로세서(CPU)가 인식하여 실행할 수 있는 기계어 명령어를 말합니다. 프로그램 개발자가 숫자로 프로그래밍하기 불편하므로 기계어와 일대일 대응되는 것이 어셈블리어입니다.
앞에서 언급했듯 우리가 다뤄볼 MIPS ISA는 RISC입니다. 현재 99% CPU가 GPR(일반목적레지스터) + Load/Store 스키마(RISC)를 사용한다고 하네요. 그에 대한 이유로는 명령어의 크기가 32bit로 고정(CPU에 따라 다르겠지만)되어 있고, 그러다보니 명령어 당 필요한 사이클의 수인 CPI(Cycle Per Instruction)가 같습니다. 이러한 것들이 파이프라인구조의 성능의 최적화를 가능하게 하기에 현재 시장을 독점하고 있다고 합니다. 자세한 내용은 새로운 글로 한번 정리하겠습니다.
그래서 이 카테고리에서는 대세를 따라 MIPS ISA를 기준으로 컴퓨터구조를 공부해보겠습니다.
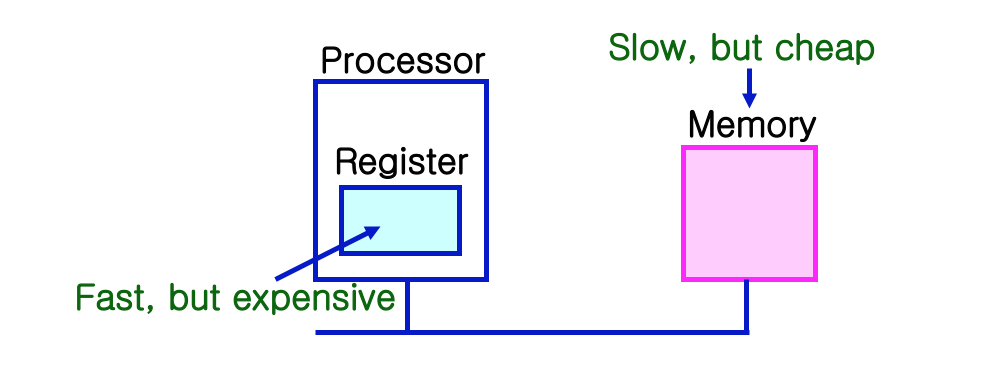
복잡한 컴퓨터 구조를 공부하면서 헷갈리지 않기 위해서는 위의 그림이 머리속에 항상 박혀있어야합니다.
위의 그림은 간단하지만 참 많은 내용이 함축되어있습니다. 일단 CPU 프로세서 안에 Register가 있다는 점. 프로세서 밖에 Memory가 있다는 점. 이 둘이 이어져있다는 것. 또한 Register가 Memory보다 가로폭이 더 넓지만 세로폭은 더 작은것도 보이네요. 그 이유는 register는 32bit 크기의 레지스터가 총 32개(GPR)있는 반면에, Memory는 16GB RAM기준 0번지부터 (2^34 - 1)번지까지 있고 각 번지의 크기는8bit이기 때문에 그렇습니다. 프로세서는 연산에 필요한 데이터를 레지스터에서 찾아보고 없으면 캐시 L1, L2, L3까지 찾아보고 그래도 없다면 메모리로 접근하여 찾아보고, 그래도 없으면 디스크로 내려갑니다. 참고로 disk I/O는 ms 스케일이고, CPU 프로세서의 연산 속도는 ns스케일입니다. 그래서 만약 disk에서 데이터 블록을 가져오는 최악의 상황이 발생한다면 10^6 만큼의 CPU의 병목이 생겨나는 것입니다. 그런데 사실 이런 케이스는 극히 드물고 데이터 블록의 지역성(locality)에 의해서 90%는 캐시 힛이 된다고 합니다.
그래도 공부 목적으로 우리는 레지스터와 메모리의 관계를 깊이 볼 필요가 있습니다.
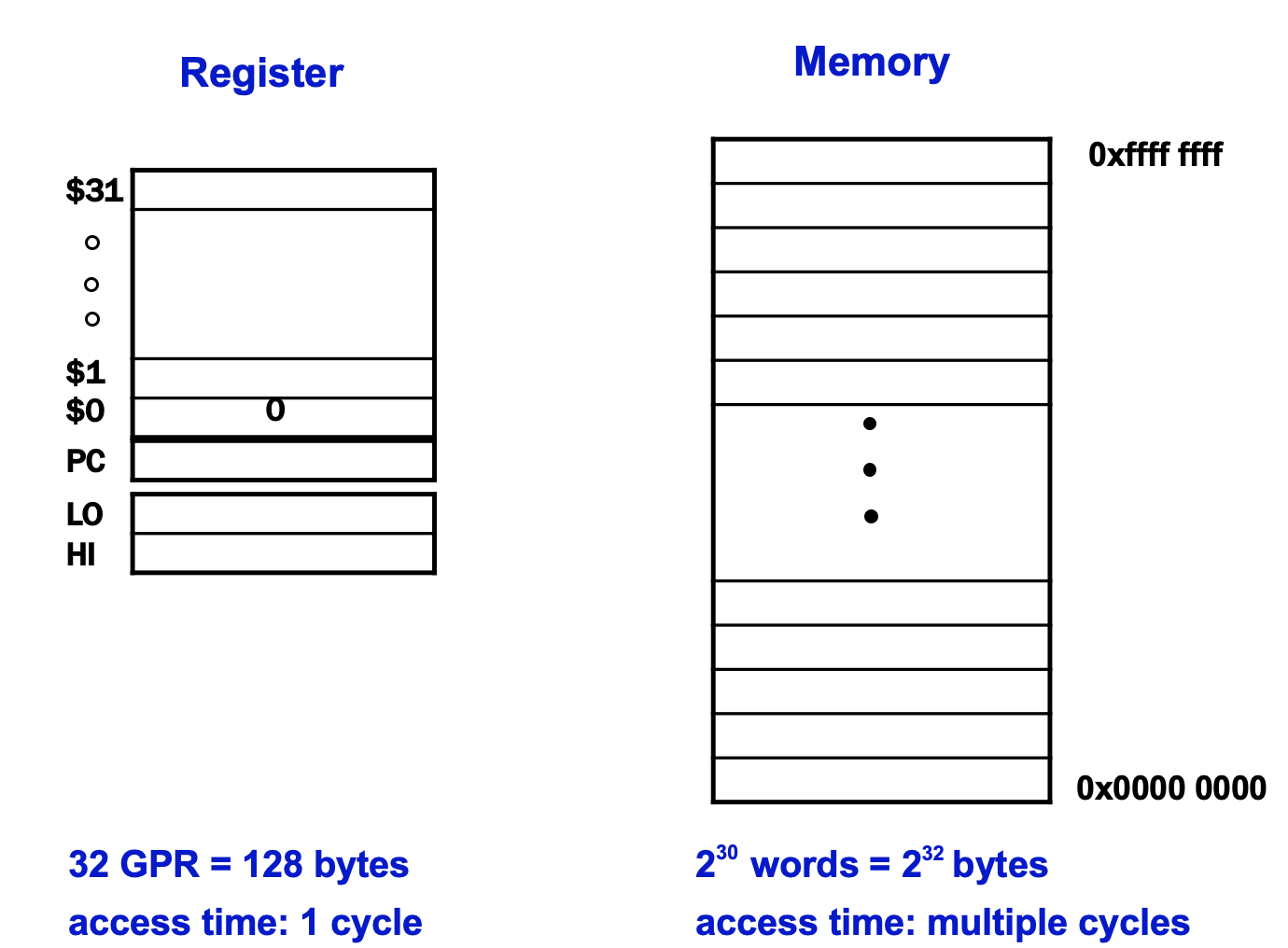
Register는 32개의 범용 레지스터 외에도 곱셈 연산을 할 때 사용되는 LO, HI 레지스터와, 현재 실행되어야할 메모리의 주소를 가리키는 PC 레지스터 이렇게 총 35개의 Register file로 구성됩니다. 그리고 프로세서 내부에 있기 때문에 CPU의 1 cycle 안에 접근 가능합니다.
Memory는 하나의 주소공간에는 8bit가 저장됩니다. 그럼 여기서 퀴즈 하나 내겠습니다. 레지스터의 크기는 32bit이고 메모리의 크기는 8bit라면 CPU가 하나의 명령어를 처리하기 위해서 메모리에서 몇개의 주소번지의 Data를 가져와야할까요?
예 맞습니다. 4개죠 그래야 8bit * 4 = 32bit를 한번 load할 때 레지스터에 다 담길 수 있겠죠. 여기서 하나의 개념이 탄생하는데. 프로세서가 명령어를 실행하기 위해서 메모리에 접근할 때 한번에 4개 번지에 있는 데이터를 가져옵니다. 그리고 이것을 1 word라고 합니다.
이제 우리는 1 word가 32bit라는 것을 외우지 않아도 이해할 수 있습니다.
자 이번 글에서는 MIPS ISA와 이를 둘러싼 레지스터와, 메모리의 관계, 그리고 프로세서의 명령어 수행을 위해 1 word를 가져오는 이유를 알아봤습니다. 다음 시간에는 오늘 배운 개념을 바탕으로 1 word(32bit)를 메모리에서 레지스터로 가져올 때 CPU가 그 기계어를 add, sub, if, branch 등으로 인식하고 operation의 종류에 따라 CPU가 연산하기 위해 필요한 3가지 Instruction format을 배워보겠습니다.